
Merhabalar, bu yazımızda Sql Server da index kullanımını inceleyeceğiz. Indexler, aradığımız bilgiyi daha az veri okuyarak daha kısa sürede getirmemizi sağlayan veritabanı nesneleridir. Sql de eğer bir tabloda index tanımlamazsak, bir bilgi aradığımız zaman Sql Server table scan adı verilen işlem ile verileri getirmektedir. Table scan ise aranan bilgiyi tüm tabloyu teker teker gezerek aramaktır. 1 milyon kayıtlı bir tabloda adı Can olan kaydı ararsak eğer table scan ile 1 milyon kaydın hepsine bakmış oluruz. Şansımız yaver gidip aradığımız kayıt ilk baktığımız olsa bile Can isimli başka bir kayıt var mı diye diğer tüm kayıtlara da table scan ile bakmış oluruz. İşte bu büyük bir maliyete sebep olmaktadır. Milyonlarca verinin tutulduğu tablolarda bu işlem büyük bir sorun teşkil edebilmektedir.
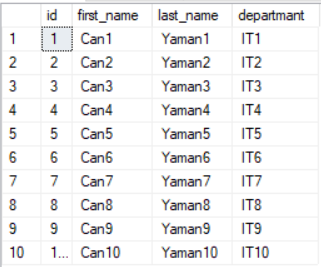
Öncelikle örnek bir tablo oluşturup bu tabloya rastgele 1 milyon kayıt ekleyelim ve ilk 10 kaydı çekip verilerin genel içeriğine göz atalım.

Yukarıda Personnels isimli bir tablo oluşturup içindeki kolonlara bir döngü yardımı ile 1 milyon kayıt eklenmiştir. Aşağıda eklenen kayıtların nasıl bir içeriğe sahip olduğu gösterilmiştir.
Şimdi 1 milyon kayıtlı Personnels tablomuzda id alanı 10 olan kaydı arayıp Sql Server’ın bu kaydı nasıl getirdiğine bakalım.
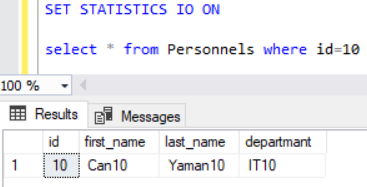
Burada SET STATISTICS IO ON komutunu kullanarak bu sorgu sonucu istatistiksel verileri görmek istediğimizi söylüyoruz. Sorgu sonucu istatistiksel veriler ise Messages kısmında yer almaktadır.
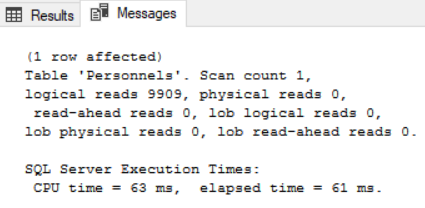
Görüldüğü üzere 10 id li kaydı bulabilmek için tam tamına 9909 sayfaya bakmaktadır. Sql Server ın en küçük yapı taşı 8 kb lık page lerdir. Burada demek istediği senin aradığın verileri bulmak için ben 9909 adet 8 kb lık pagelere baktım demektedir. 9909 adet okuma gerçekleştirdiği için 9909×8/1024 işlemi sonucunda yaklaşık 77 mb lık bir okuma gerçekleştirmiştir. Sadece bir satır için 77 mb çok yüksektir. CPU time değeri de yine bu kısımda 63 ms, geçen zaman ise 61 ms olarak yer almaktadır. Bu işlemi yerine getirirken table scan kullanılmıştır. Execution plan aşağıda gösterilmiştir.
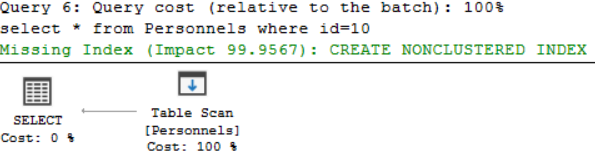
Burada sorgu için table scan ile tarama yaptığını gösteriyor. Sql Server bize index kullanımını da öneriyor ama bu konuya daha sonra değineceğiz. Şimdiye kadar index tanımlamadan 1 milyon verinin olduğu bir tabloda istediğimiz bir kaydın nasıl geldiğini, gelirken nasıl bir tarama yapıp hangi maliyetlerle bu veriyi getirdiğini gördük. Şimdi index kavramına detaylı bir şekilde değinelim.
Çok klasik bir örnek olsada telefon rehberi bu konuyu çok iyi bir şekilde açıklamaktadır. Bir telefon rehberimizin olduğunu düşünelim. Eğer buradaki kayıtlar rastgele sıralansaydı o zaman istediğimiz kaydı bulabilmek için teker teker bakmak durumunda kalırdık. Eğer kayıtlar sıralı olsaydı bu sefer yapacağımız işlem, aradığımız kaydın baş harfinin bulunduğu kısma bakmak olacaktı. İşte indexler bu şekilde verileri sıralı tutmaya yaramaktadır. Indexler binary search ile arama yapmaktadır. Binary search her bir adımda aranan değerin, dizinin orta değerine eşit olup olmadığı kontrol eder. Zaman karmaşıklığı O(log N)’ dir. Şöyle ki 1000 adet verinin olduğu bir tabloda 800. kaydı aradığımızı düşünelim. Index ile ilk önce 500. kayda gideriz. Daha sonra bakarız ve 800 ün 500 den büyük olduğunu görüp 500 den küçük tüm kayıtları aramanın dışında tutarız. Daha sonra 500 ile 1000 in ortası yani 750. kayda gelip 750 nin aşağısını da eleyip bu şekilde istediğimiz kayda ulaşabilmekteyiz.
Sql Server da temelde iki tür index bulunmaktadır. Bunlar clustered index ve non-clustered indextir. Clustered kümelenmiş sıralanmış anlamına gelmektedir.
Clustered index ile tablodaki kayıtlar fiziksel olarak sıralanmış haldedir bu yüzden clustered indexe fiziksel index de denilmektedir. Eğer bir tabloda clustered index varsa bu tablo clustered tablodur. Clustered index yoksa yani veriler sırasız ise bu tablo heap tablodur. Tablolarımızda sıkça kullandığımız auto increment primary key alanını düşünelim. Burada veriler her eklendiğinde primary key alanı bir artacak şekilde veriler tutulup, bir sıraya konulmaktadır. Bir tabloya primary key e sahip bir kolon verdiğimizde ilgili tablo otomatik olarak sıralanıp clustered index yapısına uygun hale gelmektedir yani Sql Server da primary key olarak belirlediğimiz bir kolon otomatik olarak clustered index e sahip olur. Tablomuzdaki veriler fiziksel olarak sadece bir sırayla saklanabileceği için buradan bir tabloda sadece bir tane clustered index olacağı sonucunuda çıkarmış oluyoruz. Clustered index de veriler leaf de tutulup buradan okunmaktadır.
Şimdi Personnels tablomuzdaki id alanına IX_1 adında clustered index ekleyelim. Daha sonra yine id alanı 10 olan olan kaydı çekelim.
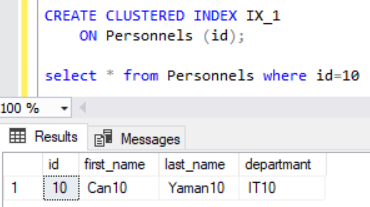
Clustered index işlemi sonrası messages kısmında yine istatistiklere göz atalım.
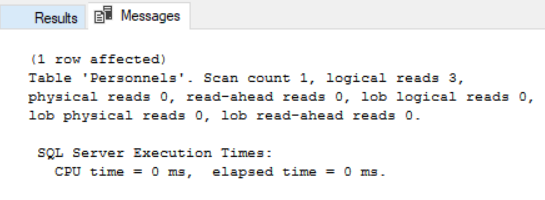
Görüldüğü gibi tablomuza clustered index eklememiz sonucunda inanılmaz bir fark oluştu. Sql Server index kullanmadan 9909 sayfaya göz atarken şimdi sadece 3 sayfaya bakarak bu işlemi gerçekleştirmiş oldu. Index kullanarak tam 3303 kat daha hızlı veriyi getirmiş olduk. Yani 3×8/1024 den 0.02 mb ile bu işlemi gerçekleştirmiş olduk. Index kullanmadan bu işlemi 77 mb ile gerçekleştirmiştik. Çok büyük boyutlu verilerin tutulduğu tabloda bu farkı hatrı sayılır şekilde hissedebilmekteyiz. Şimdi de execution planda veriyi getirirken table scan den farklı olarak nasıl bir yol izlediğine göz atalım.

Index kullanmadan önce execution planda veriyi getirirken table scan gibi maliyetli bir arama sonucu getirdiğini görmüştük şimdi ise arama yaparken tanımladığımız IX_1 adlı clustered index ile bu işlemi gerçekleştirdiğini görmekteyiz. Aradaki muazzam farklı messages kısmında da çok net bir şekilde görmüş olduk. Şimdi yine aynı tablodan bu sefer adı Can10 olan kaydı getirmeye çalışalım.
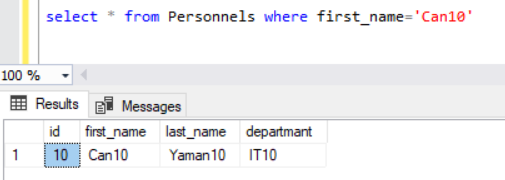
Yukarıda first_name ile yani clustered index olmayan bir kolon ile arama gerçekleştirdik. Şimdi execution plana bakalım.
Execution planda clustered index ile arama yaptığını söylüyor ama biz burda where koşulundan sonra clustered index e sahip olmayan bir kolonda arama yaptık yani Sql Server id alanına göre arama yapıp bulmuş ama bizim aradığımız alan olan first_name alanında bir index yok, haliyle o kolondaki kayıtlar sırasız bir halde. Hemen bu şekilde oluşan maliyeti görmek için messages kısmına bakalım.
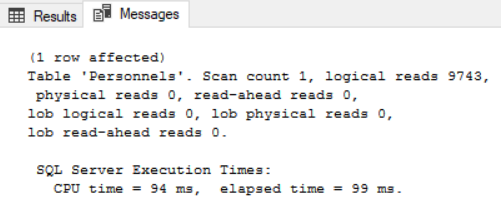
Görüldüğü üzere index olmayan bir kolonda arama yaptığımız için 9743 sayfada okuma gerçekleştirerek istediğimiz kaydı getirmiş oldu ama bu bizim istemediğimiz bir durum. Burada bu işlemi hızlandırmak için first_name kolonuna bir index tanımı yapmalıyız. Bir tabloda sadece bir tane clustered index tanımlanabileceği için bu kolona clustered index tanımlayamayız. İşte tam bu noktada non-clustered index yapısı imdadımıza yetişmektedir.
Non-clustered index, clustered index gibi verileri fiziksel olarak tutmak yerine mantıksal olarak tutmaktadır. Clustered index de veriler leaf node larda tutulurken non clustered index te leaf nodelarda verinin adresi tutulmaktadır. C dilini kullananlar var ise oradaki pointer yapısına benzetebilirler. Non-clustered index de veriye direk erişim yoktur veriler sıralandıktan sonra erişirken clustered index kullanılır. Leaf de tutulan adres kullanılarak tekrardan root node a çıkılır ve veriye erişilir.
Aşağıda non-clustered index tanımı sonrası verinin tekrar getirilmesi gösterilmiştir.
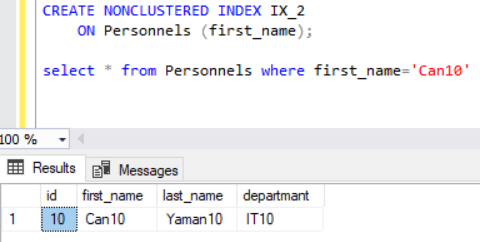
Yukarıda IX_2 adında bir non-clustered index tanımlayıp first_name i Can10 olan veriyi getirdik. Şimdi de istatistiklere bakalım.
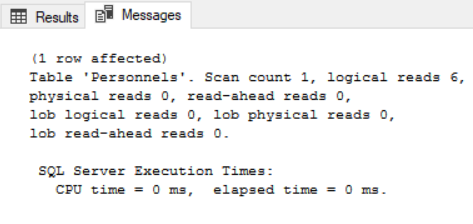
Görüldüğü gibi non-clustered index kullanmadan 9743 okuma gerçekleştirirken index sonucu sadece 6 okuma gerçekleştirdi. Yani 1623 kat daha hızlı bir şekilde ve 0.04 mb veri okuyarak bu işlemi gerçekleştirdik. Non clustered index sonucu bu işlemi nasıl gerçekleştirdiğini görmek için execution plana göz atalım.
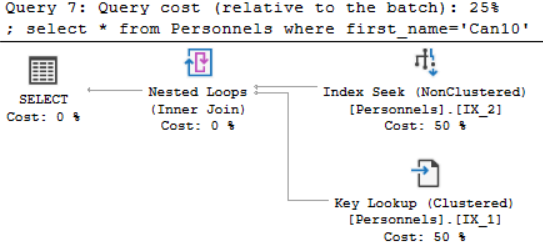
Execution planda işlemi gerçekleştirirken non-clustered index ten faydalandığını söylüyor ama buna ek olarak key lookup yaptığını söylüyor. Peki nedir bu key lookup ve neden Sql Server key lookup yapar? Bizim tablomuzda id, first_name, last_name ve departmant kolanlarımız bulunmaktadır. Bu kolonlarda id clustered, first_name non-clustered index e sahiptir. Şimdi biz first_name i ararken gidip non-clustered index yardımı ile Can10 u kolayca bulduk ama bu tabloda başka kolonlarda var last_name ve deparmant gibi. İşte burda non-clustered index te olmayan verileri yani last_name ve departmant ı getirmek için clustered index e gidip bu verileri getirmektedir. İşte bu işleme key lookup denir. Bunun da çözümü non-clustered index te olmayan kolonları buraya dahil etmektir. Bunun için included columns özelliği kullanılır.
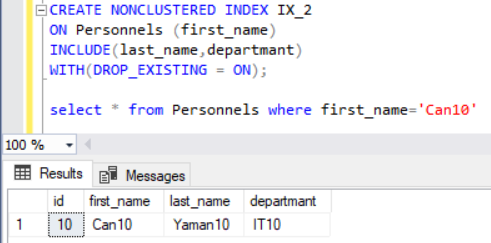
Yukarıda IX_2 isimli index e last_name ve deparmant kolonlarımızıda ekliyoruz. Buradaki amaç first_name i Can10 olan kolonu bulduktan sonra key look yapmasının önüne geçmektir.

Yukarıda artık key lookup yapacağı kolonlarda included columns ile non-clustered index e dahil olduğu için key lookup yapmadığını sadece non-clustered index ile çalıştığını görmüş olduk.
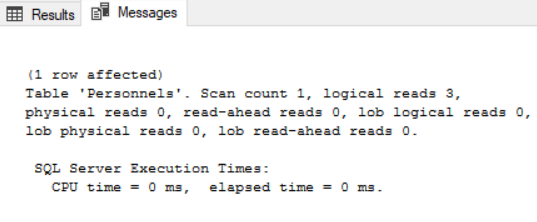
Yukarıda included columns özelliği sonrası key lookup yapmadığı için okuduğu sayfa sayısının 3 e düştüğünü görmekteyiz.
Buraya kadar index kullanmadan oluşan maliyeti index kullanarak nasıl azalttığımızı yani indexlerin ne kadar önemli olduğunu görmüş olduk. Şimdi de bu indexlerde oluşan bozulmaları inceleyip nasıl düzeltebileceğimize bakalım.
Index bozulması, index e sahip sıralanmış bir tabloya yeni kayıtların eklenmesi sonucu sıranın bozulmasına dolayısıyla amacı sıralama olan index lerin bozulmasına denilmektedir. Örnek vermek gerekirse bizim tablomuzda first_name alanındaki index o kolonu sıralamaktadır. Sıralanmış tabloya yeni bir kayıt eklendiğini varsayalım. Bu kaydın ismi Ali olsun. Baş harfi A olduğu için bu kayıt eklenirken ilgili kolonda A harfinin bulunduğu sıraya göre eklenecektir. Bu ekleme işleminin 10. satıra yapıldığını tablomuzda da 1000 kaydın olduğunu düşünelim haliyle Ali’nin eklenmesiyle 10 satır sonrası tüm kayıtlar birer satır kaydırılacaktır. 1000. kayıt için yer olmadığı için buda başka bir page e aktarılacaktır. Milyonlarca verinin olduğu bir tabloda bu işlemin çok maliyetli olacağı açıktır. İşte Sql Server bu noktada bu çok maliyetli işlemi yapmak yerine en sona yeni bir page daha ekler ve gelen verileri artık burada sırasız şekilde tutmaya başlar. Yani Ali artık A nın olduğu bölüme değil Z harfinin en sonundan sonra oluşturulacak yeni bir page e aktarılır. Bu işlem sonrası artık sıralı bir yapı yoktur, Z harfinden sonra A harfi gelmiştir dolayısıyla index yapımız bozulmuş, kayıtlar sırasız bir şekilde durmaktadır. Bu bozukluğun göstergesine fragmentation(dağılma) denilmektedir. Fragmentation oranı yüzde 30 ve yukarısında olduğu zaman artık index rebuild işlemini yapıp sıralama işlemini yeniden gerçekleştirmemiz gerekmektedir. Bizim tablolarımızda kullandığımız auto increment primary key alanı otomatik artan olduğu için gelen her kayıt zaten sona ekleneceği için primary key e sahip kolonumuzda bu sorun ile karşılaşmayız. Index bozulmasının, önüne geçip index yapımızı amacına uygun hale getirmemiz gerekmektedir.
Index bozulmalarının önüne geçmek için bazı yöntemler vardır bunlardan biri rebuild işlemidir. Rebuild, index i silip tekrar oluşturmaktadır. Belirli aralıklarla sistemimizin en az yoğun olduğu zamanlarda rebuild işlemi ile indexlerimizi tekrardan düzenleyip yeniden sıralanmış kayıtlar elde edebiliriz. Mesela her hafta pazar günü akşam 11 de bu işlemi yerine getirdiğimizi düşünelim. Eğer sistemimiz çok yoğun çalışıyorsa fragmentation yani dağılma oranı yüksek olacaktır. Bu fragmentation oranını düşürmek için fill factor kullanabiliriz. Fill factor bir index page in ne kadarının dolu olacağını belirlemektedir. Yani eğer fill factor olarak yüzde 70 değerini verirsek buna göre index pagelerimizin yüzde 30 u boş olacaktır. Haliyle yeni kayıtlar eklendiğinde bu boş alanlara yerleşecek böylece fragmentation yani dağılma oranı fill factor kullanımından önceki duruma göre daha düşük olacaktır. Bir diğer yöntem ise reorganize dır. Reorganize işleminde leaf level pagelerin tekrar sıraya sokulur. Fragmentation yüzde 30 un altındaysa reorganize üstündeyse rebuild tavsiye edilmektedir.
Aşağıda bizim tablomuzda bulunan clustered ve non-clustered indexlerin fragmentation oranlarının 0 olduğu yani hiç bozulma olmadığı yazılan sorgu sonucu gösterilmiştir.
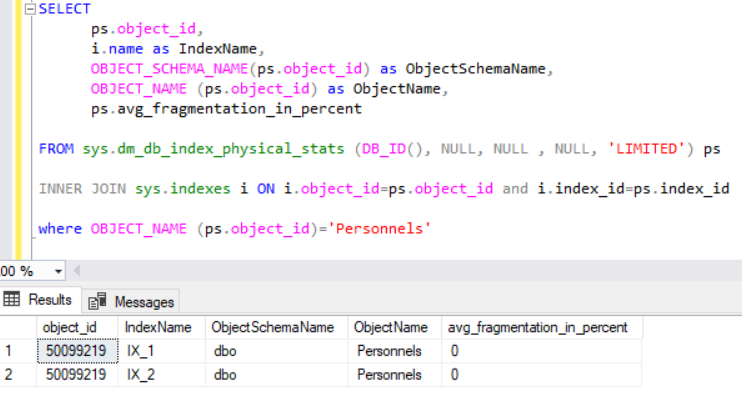
Şimdi de tablomuza 250 bin kayıt daha ekleyelim ve fragmentation oranına tekrar bakalım.
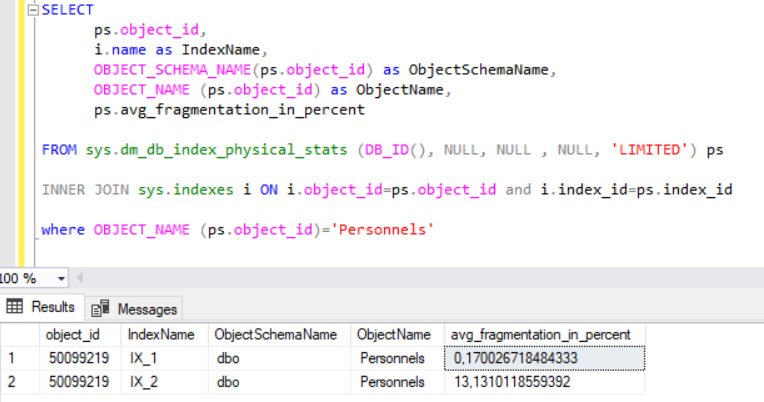
Eğer clustered index tanımladığımız kolonumuzu primary key yapsaydık IX_1 isimli indexte hiç bozulma olmayacaktı çünkü gelen her kayıt otomatik olarak sıraya konulacaktı. En sonuncu kaydın id sine bakıp 250 bin kaydı ona göre sıralı şekilde eklediğim için IX_1 index i neredeyse hiç bozulmadı ama IX_2 yani non-clustered indeximizde yüzde 13 lük bir bozulma meydana geldi. Bu bozulmaların önüne geçmek için rebuild ve reorganize kullanabileceğimizden bahsetmiştik. Bizim burda fragmentation oranlarımız yüzde 30 un altında olduğu için reorganize kullanmamız daha doğru olacaktır.
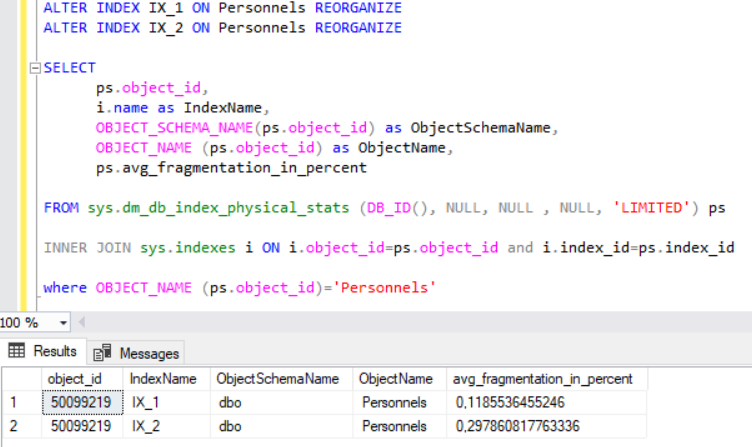
Yukarıda reorganize işlemi sonrası fragmentation oranı gösterilmiştir.
Bu işlemleri manuel olarak gerçekleştirebileceğimiz gibi Maintenance Plans sekmesinden zamanlayarak Sql Server’ın otomatik olarak gerçekleştirmesinide sağlayabiliriz.
Index lerin faydalarından bahsettik ve uygulamalı olarak görmüş olduk. Indexleri oluştururken doğru bir şekilde oluşturmakta bir hayli önemlidir. Çok kullanılan alanların indexlenmesi yararımıza olacaktır. Ayrıca indexlerin yer kapladığını unutmayıp yeterli sayıda, doğru indexleri oluşturmalıyız.
Bu yazımızda Sql Server da clustered ve non-clustered indexleri örneklerle inceledik. Bir sonraki yazılarda görüşmek üzere.
İyi çalışmalar.
